
La garantie de livraison : traverser l’océan sans perdre un octet
Dans les articles précédents, nous avons suivi la donnée depuis sa naissance sur un système AS400 jusqu’à sa transformation en JSON enrichi, prêt à être exploité par un environnement Cloud moderne.
À ce stade, les données de vente et de stock sont propres, cohérentes et stockées localement dans une file d’attente sur le serveur du magasin.
Mais elles sont toujours physiquement situées à plusieurs milliers de kilomètres du hub central.
Il reste l’étape la plus délicate de toute la chaîne : le transport sur Internet.
Entre les coupures réseau, les latences variables et les timeouts imprévisibles, comment garantir qu’aucun message ne se perde, ne soit dupliqué ou appliqué partiellement ?
La réponse tient en deux principes : un protocole de livraison strict et une sécurité pensée en profondeur.
Garantir la livraison : au-delà du simple “POST HTTP”
Envoyer une donnée via une API REST classique ne suffit pas lorsqu’on manipule des flux critiques.
Si la connexion se coupe juste après l’envoi mais avant la réponse, le système local ne sait pas si la donnée a été reçue ou non. Cela ouvre la porte soit à des doublons, soit à des pertes silencieuses.
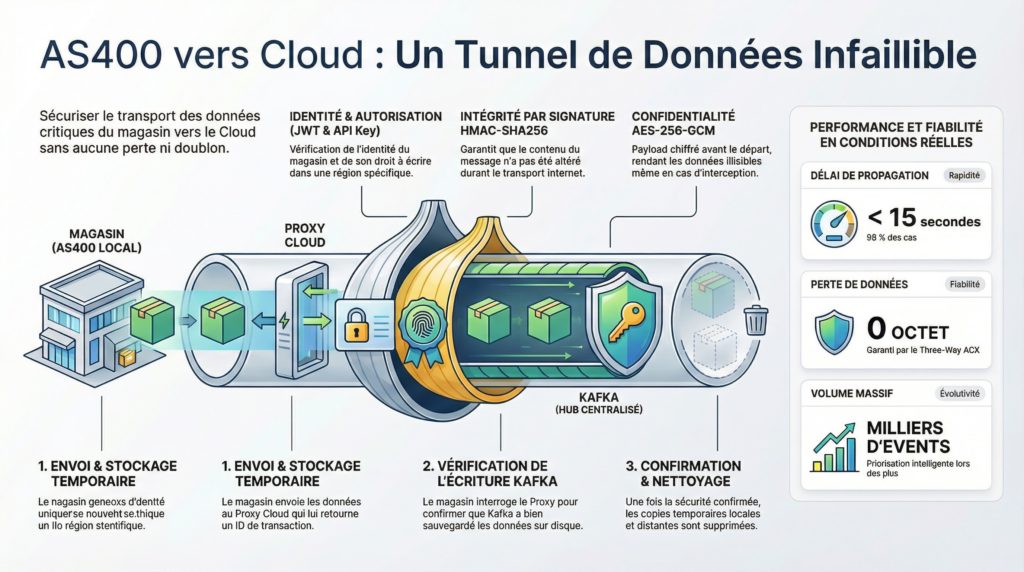
Pour éliminer cette ambiguïté, nous avons mis en place un protocole applicatif inspiré des principes du TCP, mais adapté à un contexte métier distribué.
Le dialogue entre le site émetteur et la porte d’entrée Cloud se déroule toujours en trois temps.
D’abord, la donnée est envoyée et stockée temporairement côté Cloud, avec l’attribution d’un identifiant de transaction. À ce stade, elle est reçue, mais pas encore considérée comme définitivement persistée.
Ensuite, le site émetteur interroge explicitement l’état de cette transaction. Ce n’est que lorsque le système central confirme que la donnée a été écrite de manière durable dans l’infrastructure cible que l’étape suivante peut avoir lieu.
Enfin, une confirmation finale clôt la transaction. Le site local peut alors supprimer sa copie, et la copie temporaire côté Cloud est également nettoyée.
Tant que ce cycle n’est pas entièrement terminé, la donnée est considérée comme “non livrée”. En cas de coupure réseau ou d’incident, le processus reprend sans jamais créer de doublon ni perdre un événement.
Une sécurité pensée en profondeur
Faire transiter des données d’entreprise sur Internet impose un niveau de sécurité élevé.
Ici, la protection ne repose pas sur une seule barrière, mais sur plusieurs couches complémentaires.
Avant même de parler de chiffrement, chaque message est authentifié. L’émetteur doit prouver son identité technique à l’aide d’un jeton temporaire, régulièrement renouvelé.
Ensuite, une autorisation stricte vérifie que chaque site n’écrit que dans les flux qui lui sont destinés, empêchant toute confusion entre régions ou périmètres.
Le contenu du message est également protégé contre toute altération. Une signature cryptographique permet de détecter la moindre modification en transit : un seul octet altéré suffit à invalider le message.
Enfin, la charge utile est chiffrée avant même de quitter le site émetteur. Même si le flux réseau était intercepté, les données resteraient illisibles sans les clés appropriées.
Cette approche multicouche garantit à la fois l’identité, l’intégrité et la confidentialité des données, indépendamment des aléas du réseau.
Le rôle clé de la porte d’entrée Cloud
Une fois arrivées dans le Cloud, les données ne sont pas envoyées directement dans le système central. Elles passent d’abord par un composant intermédiaire qui joue le rôle de gardien.
Ce composant ne se contente pas de relayer les messages. Il surveille en permanence l’état du système cible.
Si celui-ci montre des signes de saturation ou de ralentissement, le flux est temporairement interrompu.
Dans ce cas, les sites émetteurs reçoivent immédiatement un refus explicite et conservent leurs données localement. Elles seront renvoyées plus tard, lorsque le système central sera de nouveau en mesure de les absorber.
Ce mécanisme évite les effets d’emballement, protège l’infrastructure centrale et garantit une reprise propre après incident.
L’intégration finale dans le hub de données
Une fois la donnée acceptée par l’infrastructure centrale, elle est consommée par un dernier service chargé de l’intégration finale.
Avant toute écriture, un dernier filtrage est appliqué. Chaque événement est évalué selon son importance métier. Les changements jugés purement techniques ou sans impact opérationnel peuvent être archivés sans déclencher de mise à jour.
Les événements pertinents sont ensuite traduits en opérations de base de données. Selon que l’enregistrement existe déjà ou non, il est mis à jour ou créé.
Ce mécanisme garantit une intégration idempotente et cohérente, même en cas de relecture ou de reprise.
Performances et priorisation en conditions réelles
Entre le moment où un utilisateur modifie un prix sur son écran AS400 et celui où cette information devient visible dans la base de données centrale, le délai est généralement très court.
Dans plus de 98 % des cas, cette propagation s’effectue en moins de quinze secondes.
Ce chiffre décrit un temps de latence, et non un taux de réussite.
Sur le plan de la fiabilité, le système traite plus d’un million de messages avec seulement deux anomalies identifiées, soit un taux de livraison effectif supérieur à 99,99998 %.
Ces rares messages ne sont ni perdus ni ignorés : ils sont automatiquement détectés, tracés et conservés dans un canal dédié aux erreurs pour analyse ou retraitement.
Les délais plus longs apparaissent principalement lors de traitements massifs, le plus souvent nocturnes, lorsque plusieurs milliers — voire plusieurs dizaines de milliers — de modifications sont générées simultanément.
C’est précisément dans ces situations que le mécanisme de scoring des messages prend tout son sens.
Certains changements, bien que volumineux, ne concernent que des informations techniques sans impact métier immédiat. Ils peuvent être écartés sans conséquence, afin de garantir un traitement rapide des événements réellement critiques.
Conclusion de la série
Nous avons suivi le parcours complet d’une donnée :
Elle naît sur un système historique en magasin, est capturée sans perturber l’activité, traduite dans un format moderne, enrichie pour devenir exploitable, puis transportée de manière sécurisée et garantie jusqu’à un hub de données central.
Ce parcours démontre qu’il est possible de concilier des systèmes robustes, parfois âgés de plusieurs décennies, avec les exigences du Cloud moderne.
Non pas en les remplaçant brutalement, mais en les comprenant, en les respectant et en les intégrant intelligemment.