
De l’EBCDIC au JSON : transformer un binaire historique en format standard du Web
Dans l’article précédent, nous avons franchi une étape essentielle : réussir à lire le journal d’un AS400 sans dégrader les performances du serveur en magasin.
Mais extraire la donnée n’est qu’une première victoire.
À ce stade, ce que nous récupérons n’est pas encore exploitable. Ce sont des flux binaires bruts, parfaitement compréhensibles pour l’IBM i, mais totalement illisibles pour un système moderne.
C’est précisément le rôle de l’étape de Transformation : convertir une donnée pensée il y a plusieurs décennies en un format standard, interopérable et exploitable par le Cloud.
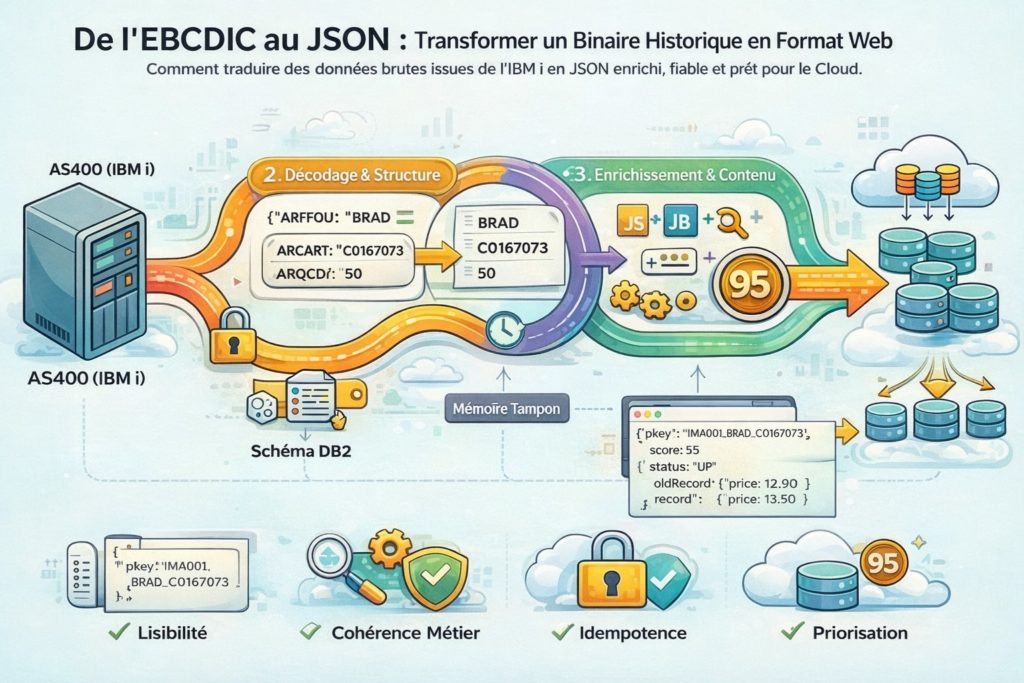
Le mur de l’EBCDIC
Ouvrir un message brut issu du journal AS400 avec un éditeur de texte classique donne souvent l’impression d’un fichier corrompu.
Ce n’est pourtant pas une erreur.
IBM i stocke ses données en EBCDIC, un encodage de caractères historique conçu bien avant l’ASCII ou l’UTF-8. À cela s’ajoutent des optimisations héritées de contraintes matérielles anciennes : champs binaires packés, zones compressées, structures dépendantes du schéma DB2.
Sans connaissance précise de la table d’origine, le flux est inexploitable. Chaque octet n’a de sens que replacé dans son contexte exact.
Décoder sans trahir la donnée
Pour transformer correctement ces données, il ne suffit pas de “convertir du texte”. Il faut rejouer la logique de stockage de l’AS400.
Le processus commence par la récupération de la définition exacte de la table source : types, longueurs, ordre des champs. Ce schéma devient la clé de lecture du flux binaire.
À partir de là, chaque octet est interprété avec la bonne table de correspondance, adaptée au contexte régional, afin de produire un texte UTF-8 fidèle à la donnée d’origine.
Ce qui n’était qu’une suite d’octets devient alors un objet structuré, lisible et cohérent.
À ce stade, la donnée est compréhensible. Mais elle n’est pas encore exploitable métier.
Le piège des mises à jour
Sur les bases modernes, une mise à jour transporte généralement l’état complet d’un enregistrement. Sur IBM i, ce n’est pas le cas.
Pour des raisons historiques d’optimisation disque, une modification est souvent découpée en deux événements distincts : l’état avant modification et l’état après modification. Pris isolément, chacun est incomplet.
Si ces événements sont propagés tels quels vers le Cloud, on introduit des incohérences, des difficultés d’audit et des erreurs d’interprétation.
La transformation doit donc réconcilier ces deux visions.
Reconstruire un événement cohérent
La solution repose sur une mémoire tampon très courte. Lorsqu’un événement représentant l’état “avant” est reçu, il est conservé brièvement. Lorsque l’état “après” arrive, les deux sont assemblés pour former un seul message cohérent.
On obtient alors une représentation complète de la modification, contenant à la fois l’ancienne valeur et la nouvelle.
Ce format est indispensable pour calculer des écarts, auditer les changements ou comprendre finement l’évolution des données.
Donner du sens : l’enrichissement
Une donnée lisible et cohérente n’est pas encore une donnée utile à l’échelle d’un hub centralisé. Elle doit être contextualisée.
L’enrichissement consiste à ajouter ce que le journal AS400 ne peut pas fournir seul : une vision globale.
C’est à ce moment que sont calculées des clés uniques capables d’identifier un enregistrement sans ambiguïté à l’échelle de plusieurs régions, magasins ou systèmes. Une référence parfaitement valide localement ne l’est plus forcément dans un environnement consolidé.
En parallèle, un mécanisme d’évaluation permet d’attribuer une priorité aux événements. Une suppression ou une variation de stock critique n’a pas le même poids qu’une mise à jour purement technique. Cette information guidera les traitements ultérieurs et les stratégies de consommation côté Cloud.
Gérer les architectures complexes sans relire la source
Dans certains contextes, une même donnée doit être répliquée logiquement vers plusieurs périmètres. Plutôt que de relire plusieurs fois le journal AS400, la duplication est effectuée à ce stade, une fois la donnée transformée.
La lecture reste unique, la charge sur le système source est maîtrisée, et la complexité est déplacée vers un environnement maîtrisé et scalable.
Bilan de l’étape Transformation
À l’issue de cette phase, la donnée a profondément changé de nature.
Elle n’est plus un flux binaire dépendant d’un système historique, mais un objet JSON standardisé, encodé en UTF-8, enrichi d’une clé globale et porteur d’une information de priorité métier.
Elle est désormais compréhensible, cohérente et prête à être consommée.
Mais elle se trouve encore localement, parfois à plusieurs milliers de kilomètres du Cloud.
👉 Dans le dernier article de cette série, nous verrons comment ces données traversent les réseaux de manière sécurisée et garantie, grâce à un protocole d’échange conçu pour ne jamais perdre un événement, même en cas de coupure.