
Série Tech : De l’AS400 au Cloud (Partie 2/4)
Le défi de l’extraction : lire un journal sans index sans mettre le serveur à genoux
Dans le premier article, nous avons survolé l’architecture globale qui permet de synchroniser nos magasins vers le Cloud.
Aujourd’hui, nous ouvrons le capot pour examiner le premier maillon critique de la chaîne : l’AS400 (IBM i).
Pour un développeur habitué aux bases de données modernes (PostgreSQL, MySQL), travailler avec un AS400 ressemble à un voyage dans le temps.
Ici, pas de CDC natif plug-and-play, ni de mécanismes pensés pour une consommation temps réel orientée Cloud.
Nous allons voir comment nous avons traité deux contraintes structurelles de l’IBM i, parfaitement déterministes mais peu adaptées à un usage CDC moderne :
- l’absence d’index sur le journal système
- la gestion purement technique des séquences
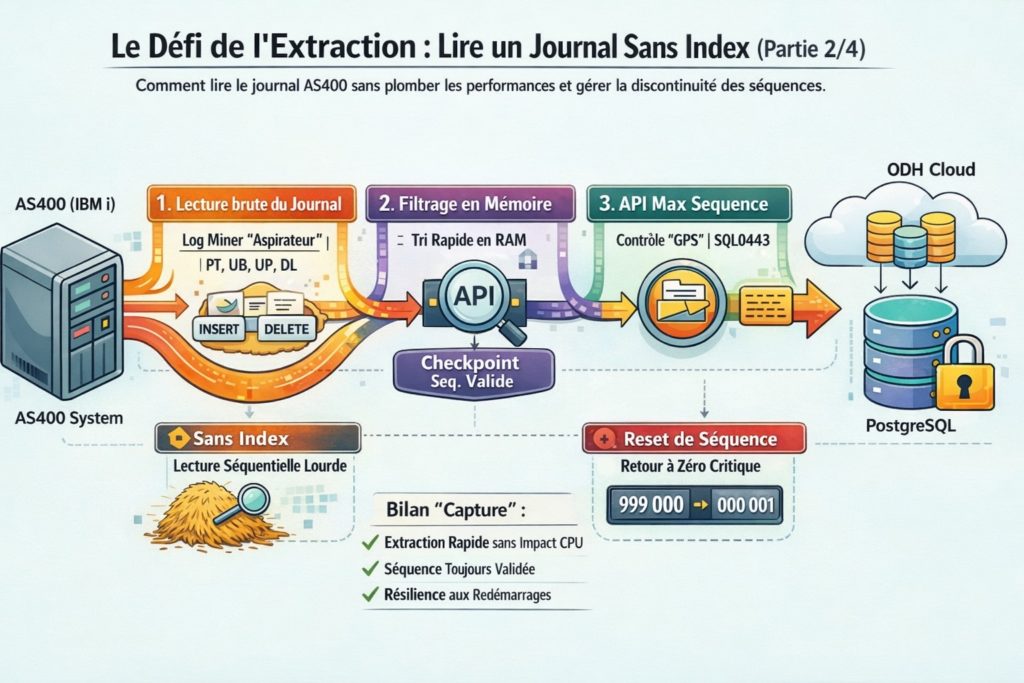
Problème n°1 : l’impossibilité du filtrage côté AS400
Le cœur de la synchronisation repose sur le journal système de l’AS400.
Ce journal est un flux séquentiel qui enregistre l’ensemble des événements de la machine.
Contrairement à une table SQL classique, ce journal :
- n’est pas indexé
- n’est pas conçu pour être interrogé de manière sélective
- est optimisé pour la reprise et l’audit, pas pour l’analyse ciblée
Toute tentative de filtrage logique côté AS400 implique donc une lecture complète et séquentielle du journal.
Or, un journal AS400 contient une quantité massive d’événements qui ne nous intéressent pas :
- connexions utilisateurs
- impressions de tickets
- opérations système
- sauvegardes et tâches techniques
Chercher uniquement les mouvements de vente ou de stock revient à inspecter chaque événement un par un, avec un coût CPU et I/O prohibitif pour un serveur magasin.
La solution : l’approche “aspirateur” (Log Miner)
Plutôt que de demander à l’AS400 de filtrer — ce pour quoi il n’est pas conçu — nous avons inversé le modèle.
Notre composant Log Miner (AS400SyncCDC) :
- lit le journal brut, sans distinction
- par fenêtres successives (par exemple 10 000 entrées à la fois)
Une fois ces blocs chargés dans la mémoire de notre application Java, nous appliquons un filtrage extrêmement rapide pour ne conserver que les opérations utiles au CDC :
- PT (Put) : insertion
- UB (Update Before) : valeur avant modification
- UP (Update After) : valeur après modification
- DL (Delete) : suppression
Sur plusieurs centaines de milliers — voire millions — d’entrées lues, seules quelques milliers sont réellement exploitables.
Cette approche permet de :
- préserver le CPU et les I/O de l’AS400
- déporter la charge vers une application scalable
- garantir des performances constantes en magasin
C’est d’ailleurs la stratégie adoptée par la majorité des implémentations CDC industrielles sérieuses sur IBM i.
Problème n°2 : la discontinuité des séquences
Lire un journal séquentiel nécessite un repère fiable : le numéro de séquence.
Il agit comme un marque-page permettant au Log Miner de reprendre exactement là où il s’est arrêté.
Cependant, sur IBM i, la continuité logique des séquences peut être rompue lors de :
- redémarrages
- maintenances
- changements ou recréations de receivers
Dans ces cas, une séquence précédemment valide peut devenir inaccessible, provoquant des erreurs critiques (ex. SQL0443).
Sans mécanisme de contrôle, cela entraîne :
- des trous de synchronisation
- des doublons
- ou un arrêt complet du processus CDC
La solution : le “GPS” des séquences (API Max Sequence)
Pour sécuriser cette étape, nous avons développé un composant dédié :
l’API Max Sequence (apiMaxSequenceDB2).
Avant chaque cycle de lecture, le Log Miner interroge cette API :
« Quelle est la dernière séquence valide actuellement disponible ? »
L’API agit comme une tour de contrôle :
- interrogation temps réel de l’AS400
- détection des ruptures de continuité
- gestion automatique des erreurs de type SQL0443
- recalage immédiat sans intervention humaine
Ainsi, même en cas de redémarrage ou de maintenance, la lecture reprend proprement sur le nouveau cycle de journal.
Résumé de l’étape “Capture”
Nous disposons désormais d’un système capable de :
- lire le journal AS400 sans impacter les performances métier
- filtrer efficacement les opérations pertinentes
- survivre aux redémarrages et ruptures de séquences
Mais une nouvelle difficulté apparaît :
les données extraites sont des octets bruts encodés en EBCDIC, totalement illisibles pour le monde Cloud.
👉 Dans le prochain article, nous verrons comment le Transformer v1 déchiffre ce format historique, reconstruit les états métiers et prépare la donnée pour les systèmes modernes.
Hello,
Où est installé le log miner, Sur l’AS400 ou sur un autre serveur ?
Merci
Bonjour sur un serveur distant. Je n’ai pas pris le risque d’essayer de le mettre sur le même serveur.
Sincères Salutations
Jean-Marc Henry