
Comment synchroniser des données magasins outre-mer vers le Cloud en temps réel ?
Dans le monde de la « Data », on parle souvent de Big Data ou d’IA, mais le vrai défi quotidien des entreprises est souvent plus terre-à-terre : comment faire communiquer des systèmes historiques robustes mais anciens avec l’agilité du Cloud ?
C’est le défi qu’a relevé notre équipe pour synchroniser les données des étiquettes electroniques et de stock de nos magasins situés dans les territoires d’outre-mer (Martinique, Guadeloupe, Réunion, Guyane, Saint-Martin) vers notre hub de données centralisé (Operational Data Hub) sur Google Cloud.
Voici comment nous avons construit un pont entre deux mondes technologiques séparés par 40 ans d’histoire et des milliers de kilomètres.
Le Défi : Faire dialoguer l’ancien et le moderne
D’un côté, nous avons des AS400 (IBM i). Ce sont des systèmes incroyablement stables, présents dans chaque magasin, qui gèrent les transactions quotidiennes. Mais ils parlent une langue ancienne (encodage EBCDIC), stockent les données dans des journaux séquentiels sans index, et redémarrent leurs compteurs de séquence à zéro sans prévenir.
De l’autre, nous avons le Cloud (GCP) et des bases de données modernes comme PostgreSQL, qui attendent des données standardisées (JSON), en temps réel, pour alimenter des tableaux de bord et des outils d’analyse.
Entre les deux ? L’océan Atlantique, des réseaux parfois instables, et un impératif absolu : ne perdre aucune donnée de vente.
La Solution : Une « Course de Relais » technologique
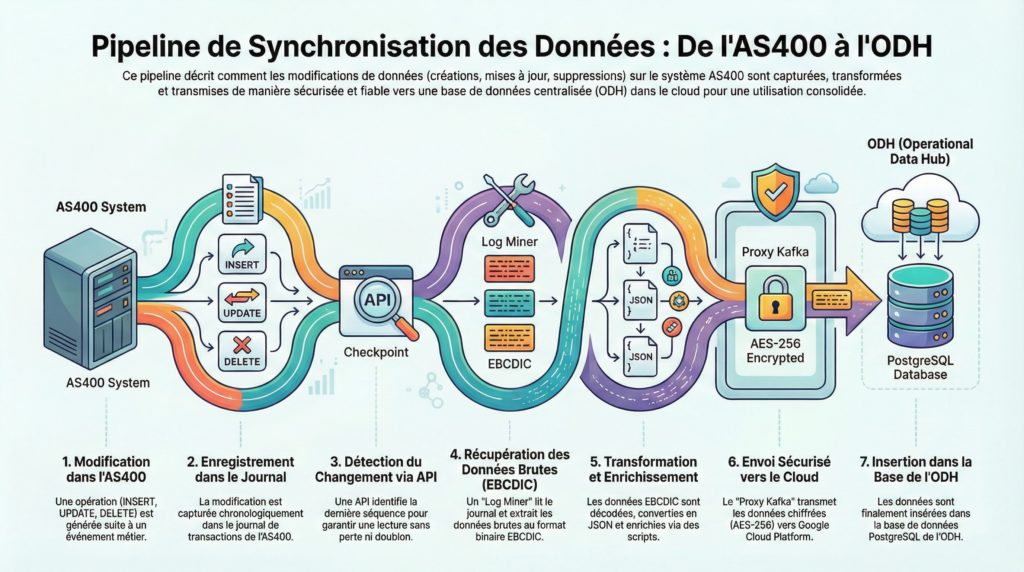
Plutôt que d’essayer de connecter directement l’AS400 au Cloud (ce qui serait lent et risqué), nous avons conçu une architecture en chaîne de relais. Chaque maillon fait une seule chose, mais la fait parfaitement.
Voici les 5 étapes du voyage d’une donnée :
1. La Capture (Le « Log Miner »)
Tout part du journal de l’AS400. Contrairement à une base de données classique où l’on ferait un SELECT *, ici c’est impossible pour des raisons de performance. Nous avons développé un agent, le Log Miner, qui lit le journal séquentiellement. Pour ne jamais perdre le fil, il s’appuie sur une API dédiée (apiMaxSequenceDB2) qui agit comme un marque-page intelligent, capable de gérer les réinitialisations de compteurs de l’AS400.
2. La Transformation (Le Traducteur)
Les données brutes extraites sont en binaire EBCDIC, illisibles pour un humain ou une machine moderne. Le service Transformer entre en jeu. Il décode ces octets en utilisant la structure des tables, réconcilie les mises à jour (l’état « avant » et « après » modification) et convertit le tout en JSON standardisé. C’est ici que la donnée devient exploitable.
3. L’Enrichissement
Avant de quitter le magasin, la donnée est enrichie. Des scripts (BeanShell ou JavaScript) ajoutent des informations contextuelles : calcul de clés primaires complexes, ajout de la région, ou calcul d’un score d’intérêt (message_interest) pour prioriser les données critiques.
4. Le Transport Sécurisé (Le Tunnel)
C’est l’étape critique du voyage vers le Cloud. Nous utilisons un composant appelé NUC Kafka Client qui applique un protocole strict de Three-Way ACK (Envoi -> Vérification -> Confirmation). Tant que le Cloud n’a pas confirmé explicitement la réception et le stockage sécurisé du message, le magasin considère qu’il n’est pas envoyé. Cela garantit une résilience totale aux coupures réseau.
5. L’Intégration (L’Atterrissage)
Une fois dans le Cloud, les données atterrissent dans un cluster Kafka géré (Managed Kafka). Un dernier service, Kafka2Database, consomme ces messages et applique les modifications dans la base PostgreSQL centrale (ODH) via des opérations d’UPSERT (mise à jour ou insertion).
Le « Gardien » de la Qualité
Comment être sûr à 100% que les stocks affichés dans le Cloud sont ceux du magasin ? En parallèle du flux temps réel, un service autonome appelé Backend-Controledatas compare périodiquement les deux mondes. S’il détecte le moindre écart, il peut déclencher automatiquement une réparation sans intervention humaine.
Conclusion
Cette architecture nous a permis de créer un système unifié : que la source soit un vieil AS400 ou une base PostgreSQL moderne, tout converge vers un point unique. C’est un système qui traite des milliers de modifications par jour, 24h/24, avec un taux de synchronisation supérieur à 98%.
Dans le prochain article, nous plongerons dans les entrailles de l’AS400 pour comprendre comment lire un journal système sans index sans mettre le serveur à genoux.